Today MLCommons® published industry results for their AI training v2.1 benchmark that contained an impressive number of submissions, with over 100 results from a wide array of industry suppliers, with roughly 90% of the entries for commercially available systems, ~10% in preview (not yet commercially available) and a few in “research,” not yet targeting commercial availability at this time. Habana® Gaudi®2 is one of three AI accelerators reporting results, with Nvidia A100 and H100 rounding out the category, with H100 in preview (not available yet).
Habana’s focus in this 2.1 benchmark is on Gaudi2, our second-generation DL processor, which launched in May and submitted leadership results on MLPerf v2.0 training ten days later. Gaudi2, produced in 7nm process and featuring 24 tensor processor cores, 96 GB on-board HBM2E memory and 24 100 integrated Gigabit Ethernet ports, has again shown leading eight-card server performance on the benchmark.
“The Habana Team is pleased that again our Gaudi2 processor has come out on top on deep learning performance among processors that submitted MLPerf DL training results in the available category. These new metrics verify the increasingly competitive performance of Gaudi2 and underscore the growing maturity of our SynapseAI software and expanding framework coverage.”
–Eitan Medina, Chief Operating Officer, Habana Labs
As shown here, Gaudi2 improved by 10% for time-to-train in TensorFlow for both BERT and ResNet-50, and reported results on PyTorch, which achieved 4% and 6% TTT advantage for BERT and ResNet-50, respectively, over the initial Gaudi2 submission. Both sets of results were submitted in the closed and available categories.
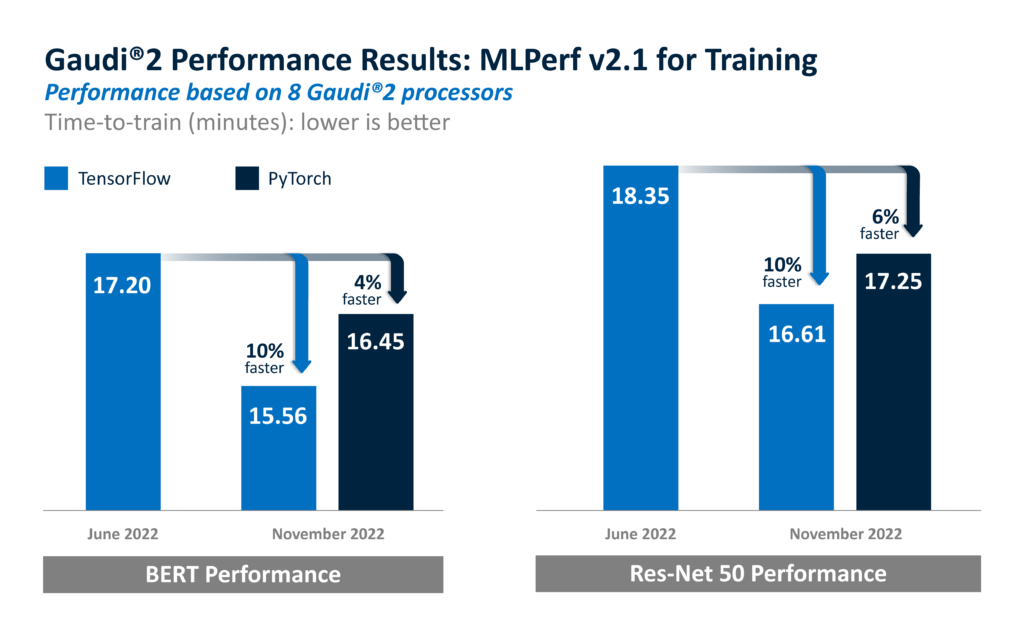
These rapid advances underscore the uniqueness of the Gaudi2 purpose-built DL architecture, increasing maturity of Gaudi2 software and expansion of the Habana SynapseAI software stack, optimized for deep learning model development and deployment.
As further evidence of the strength of the results, Gaudi2 continued to outperform the Nvidia A100 for both BERT and ResNet-50, as it did in the May submission and shown here. In addition, it’s notable that Nvidia’s H100 ResNet-50 TTT is only 11% faster than the Gaudi2 performance; and though the H100 is 59% faster than Gaudi2 on BERT, it is worth noting that Nvidia reported BERT TTT in the FP8 datatype, while Gaudi2 TTT is on the standard, verified BF16 datatype (with FP8 enablement in our software plans for Gaudi2). We believe Gaudi2 offers meaningful price-performance improvement vs. both A100 and H100.

For more info on today’s MLPerf results, please see the Intel NewsByte.
We love the competition and look forward to continued MLPerf submissions for Gaudi2 and unlocking additional features. Come by the Habana booth, #1838 at Supercomputing ’22, to see demonstration of Gaudi2 performance on leading edge models.
Performance metrics based on MLPerf v2.1 Training benchmark results.
See today’s MLCommons announcement regarding its latest benchmark.
For more information on Gaudi2, see our website and video of our live demonstration from the Intel Innovation conference.
Notices & Disclaimers
Performance varies by use, configuration and other factors.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates.
See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.