Much has happened at Habana since our last MLPerf submission in November 2021. We launched Gaudi®2, our second-generation deep learning training processor, and Greco™, our second-generation inference processor. We expanded our software functionality with SynapseAI®, which supports the latest versions of PyTorch, PyTorch Lightning, TensorFlow and openMPI. Our operator and model coverage is continually expanding and we have added many popular reference models to the HabanaAI GitHub repository, with latest examples, including Vision transformers and DeepSpeed BERT. Habana also joined forces with HuggingFace to integrate SynapseAI into the Optimum open-source library, as well as Lightning.ai to integrate SynapseAI with PyTorch Lightning. We have also integrated SynapseAI with the cnvrg.io MLOPs platform.
All the above is aimed at enabling data scientists and machine learning engineers to accelerate their training and inference jobs on Habana processors with just a few lines of code and to enjoy greater productivity, as well as lower costs, that Gaudi delivers.
Habana’s MLPerf Benchmark results
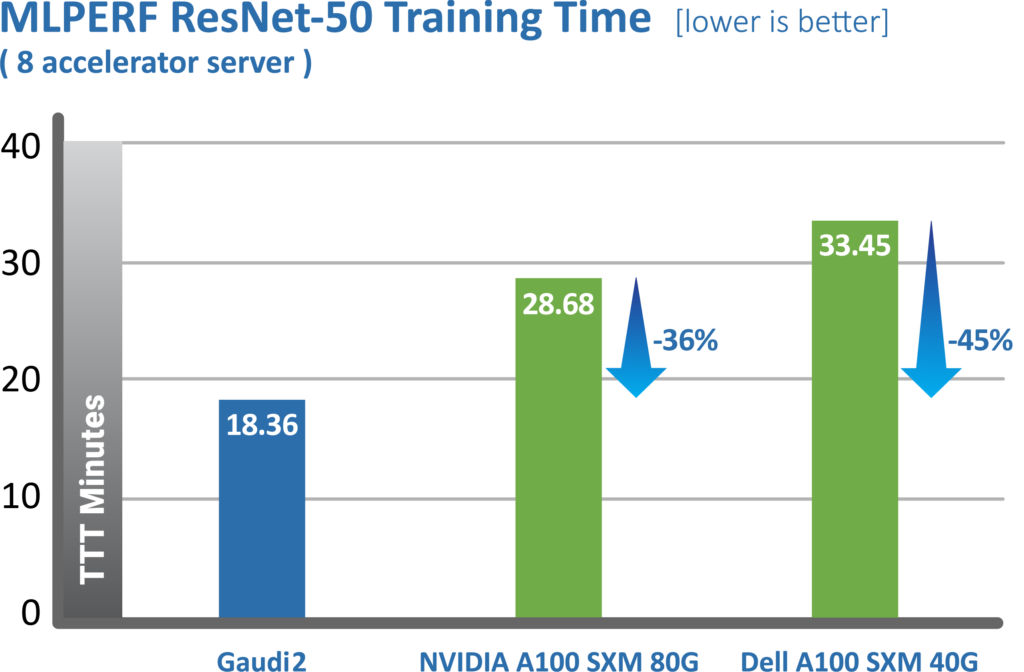
Above metrics published by MLCommons, June 2022, https://mlcommons.org/en/training-normal-20/
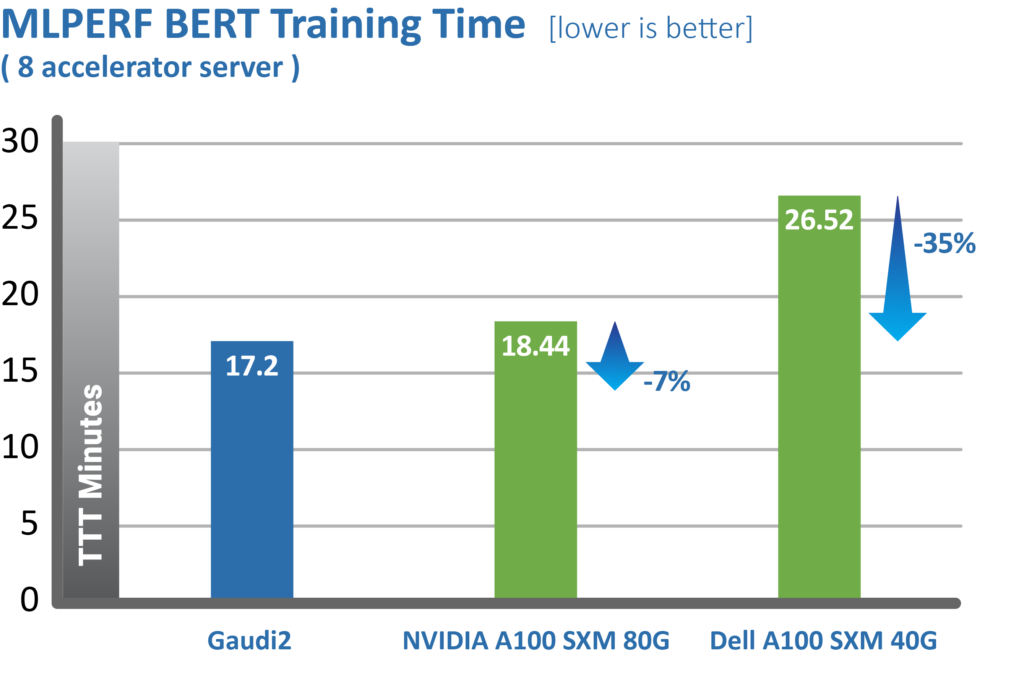
Above metrics published by MLCommons, June 2022, https://mlcommons.org/en/training-normal-20/
We’re pleased to deliver Habana’s second training submission results, including the recently launched second-generation Gaudi®2 deep learning processor, our new purpose-built AI processor that further enhances Intel’s AI XPU portfolio. Gaudi2 was launched in May and shows dramatic advancements in time-to-train, resulting in Habana’s May 2022 MLPERF submission outperforming Nvidia’s A100-80G submission for 8-card server for both the vision model (ResNet-50) and language model (BERT).
“I’m excited about delivering the outstanding MLPerf results with Gaudi2 and proud of our team’s achievement to do so just one month after launch. Delivering best-in-class performance in both vision and language models will bring value to customers and help accelerate their AI deep learning solutions.” Sandra Rivera, Intel executive vice president and general manager of the Datacenter and AI Group
For ResNet-50 Gaudi2 shows a dramatic reduction in time-to-train of 36% vs. Nvidia’s submission for A100-80GB and 45% reduction compared to Dell’s submission cited for an A100-40GB 8-accelerator server that was submitted for both ResNet-50 and BERT results.
Compared to our first-generation Gaudi, Gaudi2 achieves 3x speed-up in Training throughput for ResNet-50 and 4.7x for BERT. These advances can be attributed to the transition to the 7 nanometer processor from 16nm, tripling the number of Tensor Processor Cores, increasing our GEMM engine compute capacity, tripling the in-package high bandwidth memory capacity and increasing its bandwidth, and doubling the SRAM size. For vision models, Gaudi2 has another new feature, an integrated media engine, which operates independently and can handle the entire pre-processing pipe for compressed imaging, including data augmentation required for AI training.
Gaudi2 also includes the new FP8 datatype, which we did not apply in this MLPERF submission.
The quick and seamless launch of Gaudi2 and our ability to submit Gaudi2 in this current MLPerf evaluation were enabled due to the continued maturity of our SynapseAI® software stack. All our results were submitted over the popular TensorFlow framework under the closed division and available category. For the closed submission we used the default graph compiler optimization and measured out-of-the-box performance. We note that the high-level code we used for the previous MLPerf submission on our first-generation Gaudi®, and the current code are nearly the same, thus enabling the end-user with smooth and fast transition.
In addition to the Gaudi2 submission, we also submitted performance of 128 and 256 accelerator configurations of our first-generation Gaudi solution that demonstrate great performance and near ideal scaling linearity.
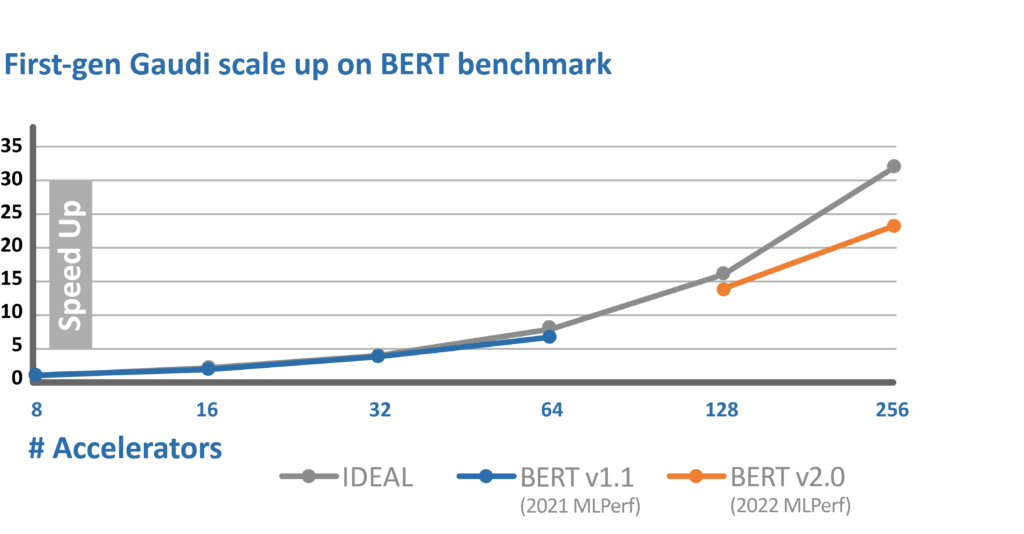
The performance of both generations of Gaudi processors is achieved without special software manipulations that differ from our commercial software stack available to Habana customers, out of the box. We note that MLPerf is a very competitive benchmark, thus some vendors apply extreme optimizations to present MLPerf performance as favorably as possible, including kernel fusion, special data loader and increased clock frequency. Disabling those optimizations with out-of-the-box code as given by our competitor (as example, see TF docker 22.03-tf2-py3 from NGC) results in substantially lower performance.
As a result of our approach to software, customers can expect to achieve MLPerf-comparable results in their own Gaudi or Gaudi2 systems using our commercially available software. Both generations of Gaudi have been designed at inception to deliver exceptional AI deep learning efficiency—so we can provide customers with the excellent performance reflected in these MLPerf results, while maintaining very competitive pricing.
For example, here is a comparison for measurements Habana produced on common 8-GPU servers vs. the HLS-Gaudi2 server throughput in training using TensorFlow dockers from NGC vs. Habana public repositories, using best parameters for performance as recommended by the vendors (mixed precision used in both). The training time throughput is a key factor in affecting the resulting training time convergence:
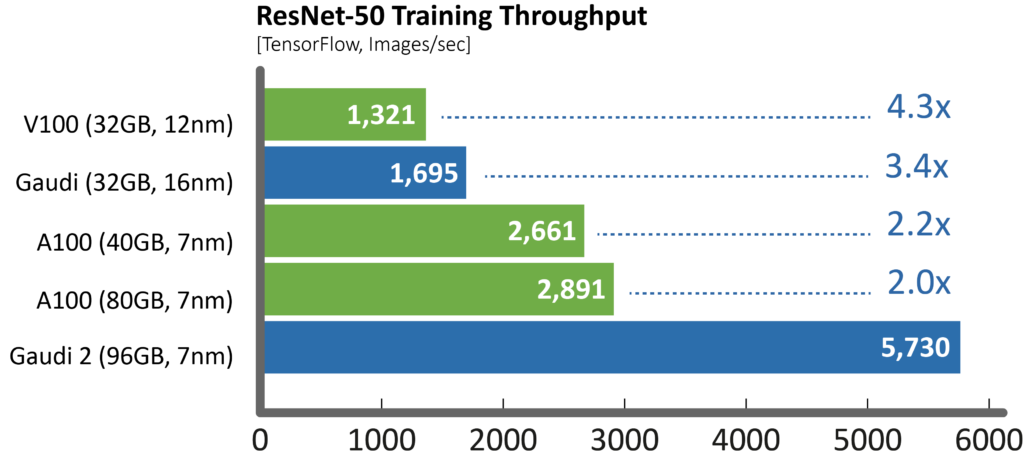
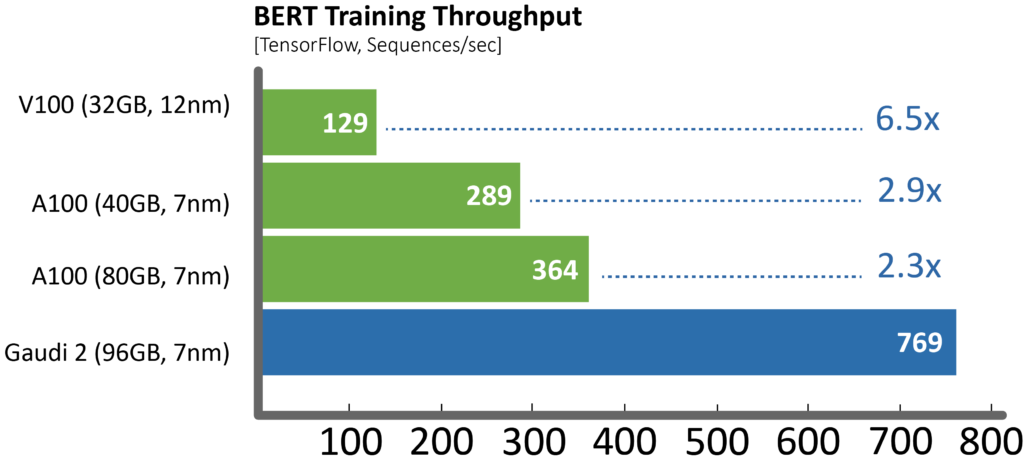
“Gaudi2 delivers clear leadership training performance in this MLPerf submission as compared to Nvidia’s A100 submission,” said Eitan Medina, chief operating officer at Habana Labs. “And the Habana team continues to innovate on our deep-learning training architecture and software to deliver highly cost-competitive AI training solutions, enabling customers to train more and spend less.”
In addition, we are pleased that Supermicro submitted Gaudi’s first OEM server results, based on the first-generation Gaudi training solution. We look forward to continuing to advance performance, efficiency, and end-user ease of use with the Gaudi platform and continue to support the MLPerf organization, our partners, and our peers in leading the future of AI.
The Technology Behind the Results
The Gaudi family compute architecture is heterogeneous and includes two compute engines – a Matrix Multiplication Engine (MME) and a fully programmable Tensor Processor Core (TPC) cluster. The MME is responsible for doing all operations that can be lowered to Matrix Multiplication (fully connected layers, convolutions, batched-GEMM), while the TPC, a VLIW SIMD processor tailor-made for deep learning operations, is used to accelerate everything else. Besides MME & TPC, Gaudi2 is also instancing several DMAs which are coupled with a transpose engine for efficient, on the fly, tensor shape transformations, in addition to the ability to read and write non-contiguous multi-dimensional tensors from and to the Gaudi2 memory subsystem.
The Gaudi2 Processor offers 2.4 Terabits of networking bandwidth with the native integration on-chip of 24 x 100 Gbps RoCE V2 RDMA NICs, which enable inter-Gaudi communication via direct routing or via standard Ethernet switching. The Gaudi2 Memory subsystem includes 96 GB of HBM2E memories delivering 2.45 TB/sec bandwidth, in addition to 48 MB of local SRAM with sufficient bandwidth to allow MME, TPC, DMAs and RDMA NICs to operate in parallel. Specifically for vision applications, Gaudi2 has integrated media decoders that operate independently and can handle the entire pre-processing pipe in all popular formats – HEVC, H.264, VP9 & JPEG, as well as post-decode image transformations needed to prepare the data for the AI pipeline.
Designed to facilitate high-performance deep learning (DL) training on Habana’s AI processors, the SynapseAI® Software Suite enables efficient mapping of neural network topologies onto Gaudi hardware family. Our SynapseAI® software stack includes Habana’s graph compiler (GC) and runtime, communication libraries, TPC kernel library, firmware, and drivers. SynapseAI is integrated with TensorFlow and PyTorch frameworks, and performance-optimized for Gaudi solutions and support for multi-device training.
The MLPerf Benchmarks
The MLPerf community aims to design fair and useful benchmarks that provide “consistent measurements of accuracy, speed, and efficiency“ for machine learning solutions. To that end AI leaders from academia, research labs, and industry decided on a set of benchmarks and defined a strict set of rules that ensure a fair comparison between all vendors. At Habana we find MLPerf benchmark is the only reliable benchmark for the AI industry due to its explicit set of rules, which enables fair comparison on end-to-end tasks. Additionally, MLPerf submissions go through a month-long peer review process, which further validates the reported results.
MLPerf Submission Divisions and Categories
MLPerf training benchmark has two submission divisions. Closed that focuses on a fair comparison—with results derived from an explicit set of assessment parameters— and “open” that allows vendors to showcase their solution(s) more favorably without the restrictive rules of the “closed”. Customers evaluating these results are also provided additional categories to help them discern which solutions are mature and commercially available (“available” category) vs. solutions not yet publicly available but coming to market at some point in the reasonably near future (”preview” category) vs. experimental/for research purposes without a defined go-to-market expectation (“research”).
More context: For more information regarding the Gaudi and Gaudi2 MLPerf benchmark results, see the latest MLPerf training results.
©Habana Labs. Habana, Habana logo, Gaudi and SynapseAI are trademarks of Habana Labs. Other names and brands may be claimed as property of others.