Today the MLPerf organization announced performance results for Inference processors and systems for the first time. Habana’s Goya has been in production since December 2018 and is reported in the Available category.
Helping readers sort out the different categories and performance metrics, MLPerf has provided an excellent paper which can be accessed here . MLPerf splits results into two divisions, closed and open. The Closed division allows for comparisons, adhering to an explicit set of rules; the open division allows vendors to more favorably showcase their solution(s) without the restrictive rules of the closed. Customers evaluating these results are also provided additional categories to help them discern which solutions are mature and commercially available (“available” category) vs. ”preview” or ”research,” categories, which include hardware/software either not yet publicly available or experimental/for research purposes. Additional data is provided for the specific hardware (processors and systems) used in running the benchmarks, including details of the number of accelerators per solution evaluated, and the complexity of the host system used to measure the inferencing results (CPU generation, air-cooling vs. water-cooling) and more.
We believe this is a great industry initiative that will truly help customers determine which solutions are actually available for them to deploy (as opposed to just “preview”), and while the report is incomplete in scope—not yet measuring power, for instance–it is a critical first step toward the industry providing standardized, valid measures. As an example, MLPERF includes the well-established vision benchmarks such as ResNet-50 and SSD-large, but it has not yet included BERT, which has achieved state-of-the-art results on many language tasks, and as such, is very popular among cloud service providers. You may refer to our BERT results here.
A single Goya HL-102 card, using passive air cooling on an affordable host, an Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz, delivers the following results, in the Available category.
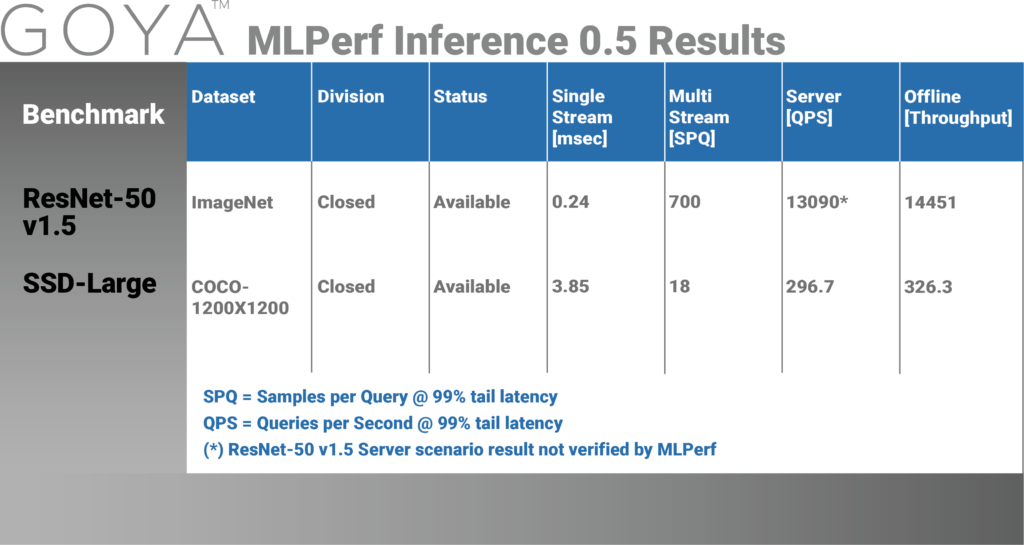
While MLPerf does not address the cost of solutions submitted, it does provide substantial foundational performance data to enable customers to determine which solutions should be evaluated for their specific applications and requirements.
In addition to the above results in the closed division, Habana has also contributed results that show Goya’s superior throughput under latency constraints, which benefits real-time applications such as autonomous driving. Such tests are available in the Open division here. Our open submission contribution follows the closed submission rules with only one change – more strict latency constraints for Multi-Stream scenario.
- ResNet-50: Goya delivers 20 Samples-Per-Query (SPQ) under latency constraint of 2ms and 40 SPQ under 3.3ms latency constraint. Thus, Goya is up to 25 times faster than the required latency for the closed division (50ms).
- SSD-large: Goya delivers 4 SPQ under latency constraint of 16.8ms and 8 SPQ under 30.8ms latency constraint, up to 4 times faster than the required latency for closed division (66ms).
Habana is proud to have actively participated in the MLPerf working group to establish performance measures and rules, and contributed workloads, driving this important effort in the service of customers and developers of technologies and products.
Additional benchmarks are available in our Goya white paper. Additional information regarding MLPerf benchmarks can be accessed here.
The MLPerf name and logo are trademarks. See www.mlperf.org for more information.