Goya outperforms T4 GPU on key NLP inference benchmark

BERT (Bidirectional Encoder Representations from Transformers) is a language representation model based on the Transformer neural architecture, introduced by Google in 2018. This approach was quickly adopted by many as it offered improved accuracy, as well as further contributed to the trend of transfer-learning with a bidirectional architecture that allows the same pre-trained model to successfully tackle a broad set of NLP tasks. Habana Labs demonstrated that a single Goya HL-100 inference processor PCIe card, delivers a record throughput of 1,527 sentences per second, inferencing the BERT-BASE model, while maintaining negligible or zero accuracy loss.
In many of today’s linguistic use cases, a vast amount of data is needed for the training process. BERT solves this issue by enabling transfer-learning on a wide variety of linguistic tasks, an approach that proved to be very efficient in computer vision. The training process is split into two phases:
1) Pre-training a base model, common to a large set of tasks and use cases, wherein a general-purpose language representation is modeled, trained on an enormous amount of unannotated text in an unsupervised fashion.
2) Fine-tuning the pre-trained base model for a specific downstream task, using relatively small amounts of data. For that purpose, the model is augmented with an additional task-specific construct, to create state-of-the-art results for a wide variety of tasks such as question answering, text summation, text classification and sentiment analysis. This fine-tuning phase benefits from substantially reduced training time and significantly improved accuracy, compared to training on these datasets from scratch.
There are several reasons why the BERT workload runs so effectively on the Goya architecture:
1. All of BERT operators are natively supported and mapped directly to the Goya hardware primitives, running without any host intervention.
2. A mixed precision implementation is deployed in order to achieve optimized performance, using Habana’s quantization tools which set the required precision per operator to maximize performance while maintaining accuracy. BERT is amenable to quantization, with either zero or negligible accuracy loss. The BERT GEMM operations are evaluated at INT16; other operations, like Layer Normalization, are done in FP32.
3. Goya’s heterogenous architecture is an ideal match to the BERT workload, as both engines, the GEMM engine and the Tensor Processing Cores (TPCs), are fully utilized concurrently, supporting low batch sizes at high throughput.
4. Goya’s TPC provides significant speedup when calculating BERT’s non-linear functions, such as GeLU (Gaussian Error Linear Unit).
5. Goya’s software-managed SRAM allows increased efficiency by optimizing data movement between different memory hierarchies while executing.
The mixed precision quantization resulted in a comparable accuracy to the original model trained in FP32, such that the accuracy drop is at most 0.11% (Verified on SQuAD 1.1 and MRPC tasks).
To quantify and benchmark BERT results we used Nvidia’s demo release, running a SQuAD Question answering task, identifying the answer to the input question within the paragraph.
Model used: Dataset: SQuAD; Topology: BERT BASE, Layers=12 Hidden Size=768 Heads=12 Intermediate Size=3,072 Max Seq Len = 128.
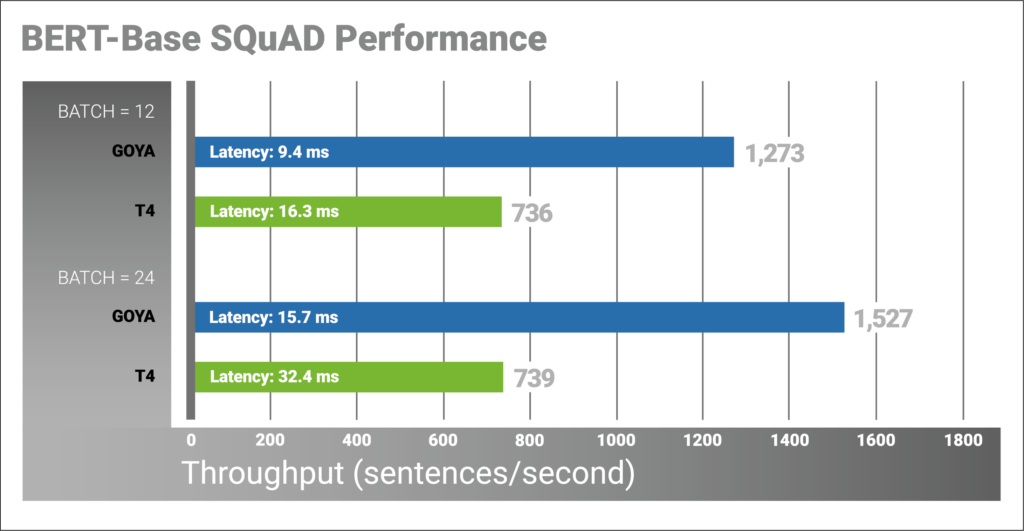
Below are the platform configurations and results:
Goya Configuration:
Hardware: Goya HL-100; CPU Xeon Gold 6152 at 2.1GHz Software: Ubuntu v-16.04.4; SynapseAI v-0.2.0–1173
GPU Configuration:
Hardware: T4; CPU Xeon Gold 6154@3Ghz/16GB/4 VMs Software: Ubuntu-18.04.2.x86_64-gnu; CUDA Ver 10.1, cudnn7.5; TensorRT-5.1.5.0;
Both the Goya and the T4 implementations are done using mixed precision of 16-bit and FP32 data types. The Habana team is working on further optimizations including uses of mixed precision data representation utilizing 8-bit data type.
The Goya processor delivers 1.67x to 2.06x (batch 12/24 respectively) higher throughput than the T4 on the SQuAD task, all at significantly lower latency. As the BERT base model is the foundation of many NLP applications, we expect similar inference speedups for other NLP applications.
To learn more about Goya performance including other benchmark results, read the Goya whitepaper.