This table provides sourcing information for the claims made in Habana content.
- PERFORMANCE CLAIMS: validation of performance claims made in Habana-published content
- THIRD-PARTY STATEMENTS: sourcing of statements or claims made by others
If you have questions regarding this content, please contact us.
| Claim | Claim Details / Citation | Test Date | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Throughput-per-Watt on BLOOMZ 176B Inference is 1.79x better than H100; 1.61x better than A100 | Based on Gaudi2 Accelerators, Nvidia A100, Nvidia H100 inference performance on BLOOMZ 176B. Gaudi2: Repo https://github.com/HabanaAI/Model References/tree/master/PyTorch/nlp/bloom, Hardware: HLS-Gaudi2 8-card Server Software: SynapseAI 1.11.0 Release; Beam size = 1; Batch size =1 Results may vary. Measured Sept 2023 Nvidia H100: Coreweave DGX H100 SXM instance; (8 GPUs) Nvidia A100: Supermicro SYS-420GP-TNAR. Repo: https://github.com/NVIDIA/FasterTransformer.git (commit c6e8f60) Card level power measured using HL-SMI and Nvidia SMI Tools. Software: NVIDIA: 525.105.17, CUDA 12.0. Beam size = 1; Batch size = 1 Results may vary. Measured Sept 2023. |
Sept 2023 | ||||||||||||||||||
| Gaudi2 Performance metrics on Llama2 | 1 Habana® Gaudi®2 Deep Learning Accelerator: All measurements were made using Habana SynapseAI version 1.10 and optimum-habana version 1.6 on a HLS2 Gaudi2 server with eight Habana Gaudi2 HL-225H Mezzanine cards and two Intel® Xeon® Platinum 8380 CPU @ 2.30GHz and 1TB of System Memory. | July 2023 | ||||||||||||||||||
| Gaud2 price-performance ~2x A100 | MLPerf Training 3.0 Results: https://mlcommons.org/en/training-normal-30/. Price-performance claims based on significant pricing differential between Intel Gaudi server and Nvidia H100 server, MLPerf Training 3.0 Results, May 2023 and internal estimates of performance advancement with FP8. Results may vary. See Supermicro for server pricing. Results may vary. |
May 2023 | ||||||||||||||||||
| Gaudi2 deliver 1.6x greater throughput-per-Watt as opposed to Nvidia A100 on inference for 176B parameter BLOOM. | Measured by Habana on the following system and software configuration: Gaudi2: Repo: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/nlp/bloom, Software: SynapseAI 1.9, Hardware: HLS-Gaudi2 Repo: https://github.com/NVIDIA/FasterTransformer.git (commit c6e8f60), Software: NVIDIA: 525.105.17, CUDA 12.0 H100: Coreweave DGX H100 SXM instance, A100: Supermicro SYS-420GP-TNAR Results may vary. |
May 2023 | ||||||||||||||||||
| Gaudi2 delivers near-linear scaling training Stable Diffusion. | 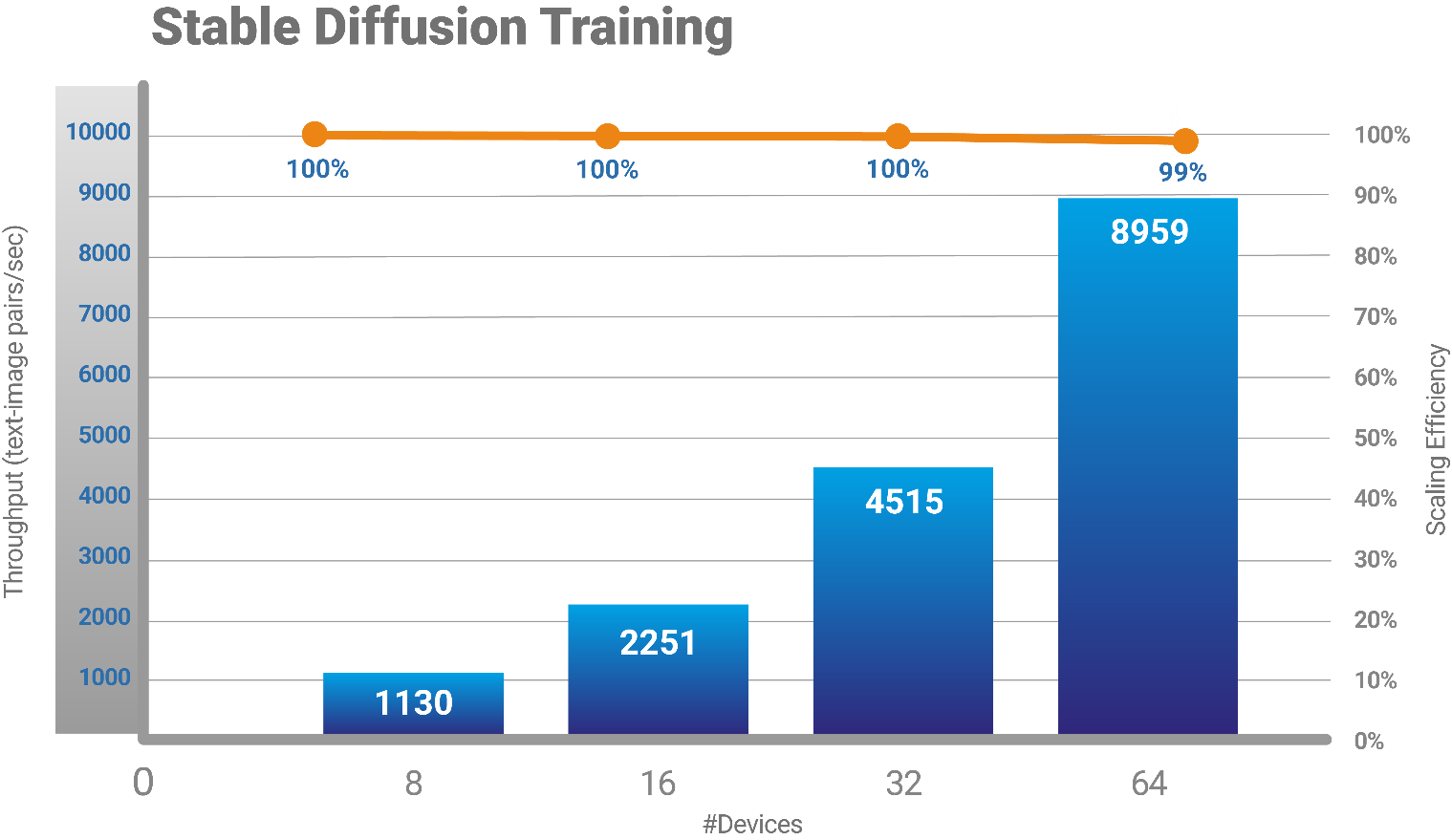 Model source: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/generative_models/stable-diffusion-training, Dataset laion2B-en. Training with BF16, batch size = 16, global batch size = 1024, for 1K iterations. Image size 256×256. Measurements using SynapseAI 1.9.0 Hardware:
|
April 2023 | ||||||||||||||||||
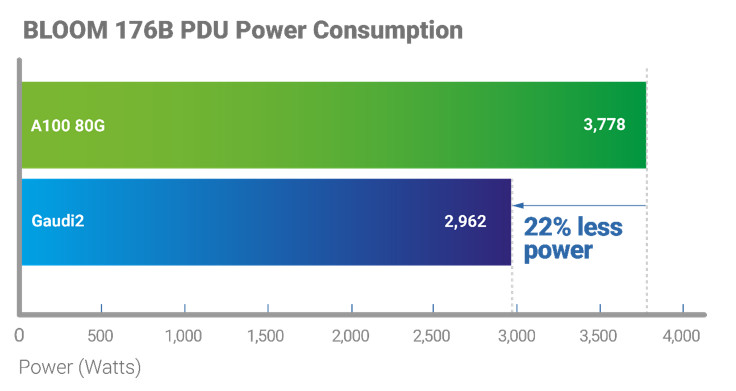
| Gaudi2 delivers 60% higher power efficiency, measured in throughput per Watt, for inferencing large language models such as Bloom-176 Billion parameter model.
Gaudi2 is 1.3X faster than A100-80G for BLOOMZ 176B inference. |
60% higher power efficiency derived from the following two factors:
Configuration used to measure power and performance: Hardware: |
April 2023 | ||||||||||||||||||
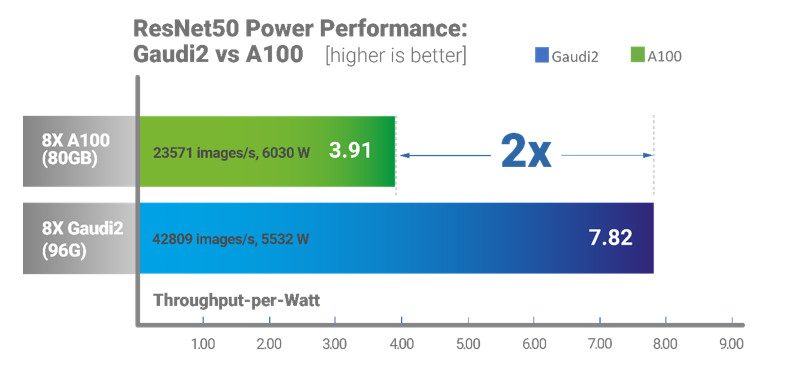
| The Gaudi2 server delivers twice the throughput-per-Watt on vision models like ResNet50 as compared to the A100-based server | Power performance measurements performed by Supermicro in their lab (April 2023). System configurations below. Results may vary.
Firmware and operating system configuration:
Hardware: Supermicro A100-based Server
|
April 2023 | ||||||||||||||||||
| Gaudi2 Out-of-the-box performance on Computer Vision and BERT | Vision:Habana ResNet50 Model: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/computer_vision/classification/torchvision
Habana SynapseAI Container: https://vault.habana.ai/gaudi-docker/1.9.0/ubuntu20.04/habanalabs/pytorch-installer-1.13.1:latest Habana Gaudi Performance: https://developer.habana.ai/resources/habana-training-models/ A100 / V100 Performance Source: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/resnet_pyt/performance ,results published for DGX A100-80G and DGX V100-32G; NLP: Habana SynapseAI Container: https://vault.habana.ai/gaudi-docker/1.9.0/ubuntu20.04/habanalabs/pytorch-installer-1.13.1:latest Habana Gaudi Performance: https://developer.habana.ai/resources/habana-training-models/ A100 / V100 Performance Sources: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/dle/resources/bert_pyt/performance ,results published for DGX A100-80G and DGX V100-32G |
March 2023 | ||||||||||||||||||
| Near-linear Scaling with Gaudi2 | Model scripts available at https://github.com/HabanaAI/Model-References Performance results available at https://developer.habana.ai/resources/habana-models-performance/ Measurements based on SynapseAI 1.9 (PyTorch 1.13.1) |
March 2023 | ||||||||||||||||||
| Linear scaling efficiency > 99% up to 64x cards | Model source: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/generative_models/stable-diffusion-training, Dataset laion2B-en. Training with BF16, batch size = 16, global batch size = 1024, for 1K iterations. Image size 256×256. Measurements using SynapseAI 1.9.0 |
March 2023 | ||||||||||||||||||
| Server power utilization comparison | HL-225H Server: SYS-820-GH-TNR2; CPU: 2x Intel Xeon Platinum 8380; Memory: 16 Samsung 3200 MHz 64GB; DL Processor – 8x Gaudi2 HL-225H 96 GB; Storage: 7.7TB NVME SSD + 800 GB HDD; Operating system: Ubuntu 22.04; FW revision: 76.00.04; BIOS version: 1.4; CPLD f1.0c.08
A100 Server: AS-4123GO-NART+; CPU: 2x AMD EPYC 7763; Memory: 16x Micron 3200 MHz 64 GB, GPU: 8x A100-SXM-80 GB; Storage: 3.5TB NVME SSD; Operating system: Ubuntu 22.04; FW revision 06.00.20; BIOS version: 1.02; CPLD version f1.05.02 |
October 2022 | ||||||||||||||||||
| Performance metrics published by Regis Pierrard, Hugging Face, in his blog: https://huggingface.co/blog/habana-gaudi-2-bloom | Habana Model scripts: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/nlp/bloom
Model performance: https://developer.habana.ai/resources/habana-models-performance/, Measured using SynapseAI 1.9.0. GPU model scripts: https://huggingface.co/blog/bloom-inference-pytorch-scripts All measurements using batch size = 1, max length = 128. Results may vary. |
March 2023 | ||||||||||||||||||
| Gaudi2 inference is 2.44x faster than A100-80G on Stable Diffusion v2 from Hugging Face diffusers | https://huggingface.co/blog/habana-gaudi-2-benchmark#generating-images-from-text-with-stable-diffusion
Habana Model scripts: https://github.com/HabanaAI/Model-References/tree/master/PyTorch/generative_models/stable-diffusion-v-2-1. Model performance: https://developer.habana.ai/resources/habana-models-performance/ Measured with SynapseAI 1.9.0 using BF16, batch size = 1, 50 steps with DDIM sampler. Results may vary. |
March 2023 | ||||||||||||||||||
| Gaudi2 is 1.5 – 2x faster than A100 for both training and inference. | Habana ResNet50 Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/computer_vision/Resnets/resnet_keras Habana SynapseAI Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.7.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.8.3 Habana Gaudi Performance: https://developer.habana.ai/resources/habana-training-models/ A100 / V100 Performance Source: https://ngc.nvidia.com/catalog/resources/nvidia:resnet_50_v1_5_for_tensorflow/performance, results published for DGX A100-40GB and DGX V100-32GB Habana BERT-Large Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/nlp/bert Habana SynapseAI Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.7.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.8.3 Habana Gaudi Performance: https://developer.habana.ai/resources/habana-training-models/ A100 / V100 Performance Sources: https://ngc.nvidia.com/catalog/resources/nvidia:bert_for_tensorflow/performance, results published for DGX A100-40G and DGX V100-32G Measured January 2023 |
January 2023 | ||||||||||||||||||
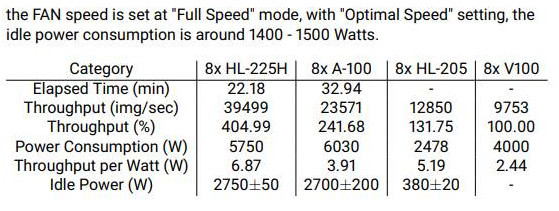
| Gaudi2 delivers ~1.8x higher throughput/Watt vs A100 | Based on evaluation by Supermicro. Following is the configuration used in the evaluation. Hardware configuration Habana Gaudi2 Server; HL-225H Server; Part number: SYS-820GH-TNR2 , CPU: 2x Intel Xeon Platinum 8380; Memory: 16x Samsung 3200 MHz 64GB, AI Processor: 8x Gaudi2 HL-225H 96GB, Storage: 7.7TB NVME SSD + 800GB HDD. Gaudi2 Server software: Ubuntu – 20.04, FW Revision 76.00.04, BIOS Version 1.4, CPLD Version f1.0c.08. Firmware: hl-1.6.1-fw-37.2.0; driver: 1.6.1-2a51fee; System firmware build time: 2022/10/04 v76.00.04; System BIOS build time: 2022/09/13 v1.4; Running ResNet-50 v 1.5, TensorFlow 2.8.3 Hardware configuration Nvidia A100: Features 8 A100-SXM-80GB Nvidia GPUs; Host: 2x AMD EPYC 7763 Software Nvidia A100: A100 Server software: Ubuntu 20.04, FW Revision 06.00.20, BIOS Version 1.02, DPLD f1.05.02; Ran ResNet-50 v 1.5, MxNET
Additionally, the firmware version, BIOS version, CPLD version and Operating System information of the comparison group are listed in the Table 4 below. The different version of firmware, BIOS and CPLD version is due to different server types as well as various customers’ requirement. For numerical results we the chart below. Note:
|
October 2022 | ||||||||||||||||||
| Third party evaluation by Hugging Face for both training and inference: | https://huggingface.co/blog/habana-gaudi-2-benchmark | December 2022 | ||||||||||||||||||
| Performance metrics for ResNet-50, Gaudi2 vs Nvidia A100 | ResNet-50 Performance Comparison: Habana ResNet50 Model: https://github.com/HabanaAI/ModelReferences/tree/master/TensorFlow/computer_vision/Resnets/resnet_keras Habana SynapseAI Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.7.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.8.3 Habana Gaudi Performance: https://developer.habana.ai/resources/habana-training-models/ A100 / V100 Performance Source: https://ngc.nvidia.com/catalog/resources/nvidia:resnet_50_v1_5_for_tensorflow/performance, results published for DGX A100-40G and DGX V100-32G Results may vary. |
January 2023 | ||||||||||||||||||
| Performance metrics for BERT Pre-training, Gaudi2 vs Nvidia A100 | BERT Pre-Training Performance Comparison: Habana BERT-Large Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/nlp/bert Habana SynapseAI Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.7.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.8.3 Habana Gaudi Performance: https://developer.habana.ai/resources/habana-training-models/ A100 / V100 Performance Sources: https://ngc.nvidia.com/catalog/resources/nvidia:bert_for_tensorflow/performance results published for DGX A100-40G and DGX V100-32G Results may vary. |
January 2023 | ||||||||||||||||||
| Gaudi2 performance 2x relative to A100:Gaudi2: BERT Phase-1 Training – sequences per-second throughput: 1.7X relative to A100 (80GB); 2.1x relative to A100 (40GB); 4.5x relative to V100 | Gaudi2 sequences-per-second throughput on BERT Phase-1 Training: – A100-80GB : Measured by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB with TF docker 21.02-tf2-py3 from NGC (Phase-1: Seq len=128, BS=312, accu steps=1024; Phase-2: seq len=512, BS=40, accu steps=3072) – A100-40GB : Measured by Habana on DGX-A100 using single A100-40GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) – V100-32GB : Measured by Habana on p3dn.24xlarge using single V100-32GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096) – Gaudi2: Measured by Habana on Gaudi2-HLS system using single Gaudi2 with SynapseAI TF docker 1.4.0-435 (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) Results may vary. | April 2022 | ||||||||||||||||||
| Gaudi2 performance 2x relative to A100: Gaudi2 BERT Phase-2 Training – sequences-per-second throughput: 2.8x relative to A100 (80GB); 3.3x relative to A100 (40GB); 7.7x relative to V100. | Gaudi2 sequences-per-second throughput on BERT Phase-1 Training: – A100-80GB : Measured by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB with TF docker 21.02-tf2-py3 from NGC (Phase-1: Seq len=128, BS=312, accu steps=1024; Phase-2: seq len=512, BS=40, accu steps=3072) – A100-40GB : Measured by Habana on DGX-A100 using single A100-40GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) – V100-32GB : Measured by Habana on p3dn.24xlarge using single V100-32GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096) – Gaudi2: Measured by Habana on Gaudi2-HLS system using single Gaudi2 with SynapseAI TF docker 1.4.0-435 (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) Results may vary. | April 2022 | ||||||||||||||||||
| Gaudi2 performance 2x relative to A100: Gaudi2 BERT Effective Throughput Combining Phase-1 and Phase-2 (per standard industry practice) – sequences-per-second :2.x relative to A100 (80GB); 2.4x relative to A100 (40GB); 5.3x relative to V100. | Gaudi2 sequences-per-second on BERT Effective Throughput combining Phase-1 and Phase-2: A100-80GB : Measured by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB with TF docker 21.02-tf2-py3 from NGC (Phase-1: Seq len=128, BS=312, accu steps=1024; Phase-2: seq len=512, BS=40, accu steps=3072) – A100-40GB : Measured by Habana on DGX-A100 using single A100-40GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) – V100-32GB : Measured by Habana on p3dn.24xlarge using single V100-32GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096) – Gaudi2: Measured by Habana on Gaudi2-HLS system using single Gaudi2 with SynapseAI TF docker 1.4.0-435 (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) Results may vary. | April 2022 | ||||||||||||||||||
| Enterprises will increasingly rely on deep learning; 2021 – 2026 projections indicate: Data center accelerator market CAGR of 36.7%; 1/3 of servers shipped in 2026 will run DL training or inference; DL to acount for majority of cloud workloads; training applications to be the majority of the server apps by | Source: https://www.businesswire.com/news/home/20210819005361/en/Global-Data-Center-Accelerator – Market-Forecast-to-2026-Artificial-Intelligence-to-Drive-the-Growth-of-Cloud-Data-Center-Market. ResearchAndMarkets.com | |||||||||||||||||||
| “On our own models the increase in price performance met and even exceeded the published 40% mark.” | Quote by Rand Chaim, Mobileye, ML Algorithm Engineer, based on Mobileye evaluation of Gaudi-based DL1; https://towardsdatascience.com/training-on-aws-with-habana-gaudi-3126e183048 | |||||||||||||||||||
| Gaudi2 performance relative to A100: Gaudi2 images-per-second throughput on ResNet-50: 1.9x relative to A100 (80GB); 2.0x relative to A100 (40GB); 4.1x relative to V100; | RESNET50 CLAIM: Sources for performance substantiation for ResNet-50: (note that the ResNet-50 model script is also run as a live demonstration to show the Gaudi2 performance which conforms with the test configuration noted below. A100-80GB : Measured by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB using TF docker 21.12-tf2-py3 from NGC (optimizer=sgd, BS=256) – A100-40GB : Measured by Habana on DGX-A100 using single A100-40GB using TF docker 21.12-tf2-py3 from NGC (optimizer=sgd, BS=256) – V100-32GB : Measured by Habana on p3dn.24xlarge using single V100-32GB using TF docker 21.12-tf2-py3 from NGC (optimizer=sgd, BS=256) – Gaudi2:Measured by Habana on Gaudi2-HLS system using single Gaudi2 using SynapseAI TF docker 1.4.0-435 (BS=256) Results may vary. | April 2022 | ||||||||||||||||||
| Customer savings with Gaudi-based Amazon DL1 instances ResNet-50 $/image throughput cost: DL1 – 46% lower than A100-based P4d DL1 – 60% lower than V100-based P3 BERT-Large Pre-Training Phase-1 $/sequence throughphput cost: DL1 – 31% lower than A100-based P4d DL1 – 54% lower than V100 -based P3 BERT-Large Pre-Training Phase-2 $/sequence throughput cost: DL1 – 57% lower than A100-based P4d DL1 – 75% lower than A100-based P3 |
Cost savings based on Amazon EC2 On-Demand pricing for P3, P4d and DL1 instances respectively. Performance data was collected and measured using the following resources. Results may vary. Habana BERT-Large Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/nlp/bert | September 2021 | ||||||||||||||||||
| While Gaudi2 is implemented in the same 7nm process as the A100, it delivers twice the throughput for both ResNet50 and BERT models, the two most popular vision and language models. | RESNET50 CLAIM: Sources for performance substantiation for ResNet-50: (note that the ResNet-50 model script is also run as a live demonstration to show the Gaudi2 performance which conforms with the test configuration noted below. A100-80GB : Measured by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB using TF docker 21.12-tf2-py3 from NGC (optimizer=sgd, BS=256) – A100-40GB : Measured by Habana on DGX-A100 using single A100-40GB using TF docker 21.12-tf2-py3 from NGC (optimizer=sgd, BS=256) – V100-32GB : Measured by Habana on p3dn.24xlarge using single V100-32GB using TF docker 21.12-tf2-py3 from NGC (optimizer=sgd, BS=256) – Gaudi2:Measured by Habana on Gaudi2-HLS system using single Gaudi2 using SynapseAI TF docker 1.4.0-435 (BS=256) Results may vary. BERT CLAIM: Effective throughput combining Phase-1 and Phase-2 – A100-80GB : Measured by Habana on Azure instance Standard_ND96amsr_A100_v4 using single A100-80GB with TF docker 21.02-tf2-py3 from NGC (Phase 1: Seq len=128, BS= 312, accu steps=1024; Phase-2: seq len=512, BS=40, accu steps=3072) – A100-40GB : Measured by Habana on DGX-A100 using single A100-40GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) – V100-32GB : Measured by Habana on p3dn.24xlarge using single V100-32GB with TF docker 21.12-tf2-py3 from NGC (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=8, accu steps=4096) – Gaudi2: Measured by Habana on Gaudi2-HLS system using single Gaudi2 with SynapseAI TF docker 1.4.0-435 (Phase-1: Seq len=128, BS=64, accu steps=1024; Phase-2: seq len=512, BS=16, accu steps=2048) Results may vary. | April 2022 | ||||||||||||||||||
| 3rd party stat: . 74% of IDC ML practitioner respondents indicate running 5 – 10 iterations of training 50% of ML practitioner respondents rebuilt models weekly or more often; 26% rebuild daily or hourly 56% cite cost of AI training as most significant challenge to implementing AL/ML solutions” | source: IDC Semiannual Artificial Intellilgence Tracker (2020H1) | |||||||||||||||||||
| In reference to the Gaudi-based DL1 instance: Up to 40% better price performance than latest GPU-based instances | The price/performance claim is made by AWS and based on AWS’s internal testing. Habana Labs does not control or audit third-party data. More information can be found at: https://habana.ai/blog/aws-launches-ec2-dl1-instances/. Customer claim: https://press.aboutamazon.com/news-releases/news-release-details/aws-announces-general-availability-amazon-ec2-dl1-instances | |||||||||||||||||||
| DL1 ResNet-50 Performance vs. A100 and V100: we compare training throughput running ResNet50 using Tensorflow The GPU performance and configuration are reported by nVidia on DGX machines, that are similar (but not identical) to the instances offered by AWS. | Configuration of performance test: Habana ResNet50 Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/computer_vision/Resnets/resnet_keras Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.2.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.7.0 Habana Gaudi Performance: https://developer.habana.ai/resources/habana-models-performance/ A100 / V100 Performance Source: https://ngc.nvidia.com/catalog/resources/nvidia:resnet_50_v1_5_for_tensorflow/performance, results published for DGX A100-40G and DGX V100-32G Results may vary. |
September 2021 | ||||||||||||||||||
| DL1 NLP BERT Performance vs. A100 and V100: we compare training throughput running BERT using TensorFlow. (The GPU numbers are reported by Nvidia on DGX machines, that are similar (but not identifcal) to the instances offered by AWS. | Habana BERT-Large Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/nlp/bert Habana SynapseAI Container: https://vault.habana.ai/ui/repos/tree/General/gaudi-docker/1.2.0/ubuntu20.04/habanalabs/tensorflow-installer-tf-cpu-2.7.0 Habana Gaudi Performance: https://developer.habana.ai/resources/habana-models-performance/ A100 / V100 Performance Sources: https://ngc.nvidia.com/catalog/resources/nvidia:bert_for_tensorflow/performance, results published for DGX A100-40G and DGX V100-32G |
September 2021 | ||||||||||||||||||
| Customer savings with Gaudi-based Amazon DL1 instances ResNet-50 $/image throughput cost: DL1 – 46% lower than A100-based P4d DL1 – 60% lower than V100-based P3 BERT-Large Pre-Training Phase-1 $/sequence throughphput cost: DL1 – 31% lower than A100-based P4d DL1 – 54% lower than V100 -based P3 BERT-Large Pre-Training Phase-2 $/sequence throughput cost: DL1 – 57% lower than A100-based P4d DL1 – 75% lower than A100-based P3 |
Cost savings based on Amazon EC2 On-Demand pricing for P3, P4d and DL1 instances respectively. Performance data was collected and measured using the following resources. Results may vary. Habana BERT-Large Model: https://github.com/HabanaAI/Model-References/tree/master/TensorFlow/nlp/bert | September 2021 | ||||||||||||||||||
| DL1 Cost savings calculated by Leidos in conducting POC on medical imaging workloads; Cost savings of 59% with DL1 on ChexNET-Keras model | Source: Leidos Configuration: Pre-training model: CheXNet-Keras; Dataset: ChestXray – NIHCC; batch size: 32; Precision: FP32; Device count: 8 Gaudi-based DL1.24xlarge instances vs. 8x V100-32 GB (p3dn.24xlarge) | |||||||||||||||||||
| DL1 Cost savings calculated by Leidos in conducting POC on medical imaging workloads; cost savings of 67% with DL1 on COVID-CXNet | Source: Leidos Configuration: Pre-training model: COVID-CXNet; Dataset: COVID-CXNet; Batch size: 16; Precision: BF16; Device count: 1; | |||||||||||||||||||
| 3rd Gen Xeon (codenamed Ice Lake) Measurements on 3-node 2S 32 core, 2.5GHz, 300W TDP SKU with 512GB DDR4 RAM and 40Gbps network. | ||||||||||||||||||||
| Single socket server with 3rd gen Xeon Scalable general purpose cpu can finishes the End to End – Single Cell -Genomics sequencing in 489 seconds compared with 686 seconds an Nvidia A100 GPU. This means 3rd gen Xeon Scalable is 1.4x faster than Nvidia A100, that equates to over 1.6x better TCO. Single socket server with the next gen general purpose cpu can finish the End to End – Single Cell -Genomics sequencing workload in 370 seconds compared with 686 seconds an Nvidia A100 GPU. This means we can deliver nearly 2x the performance of Nvidia’s mainstream Training GPU for 2022. | Baseline Testing as of Dec16th 2020. Google Cloud instance a2-highgpu-1g, 1x Tesla A100 GPU, 40GB HBM2 Memory, 12 vCPUs, $3.78 cost per hour, dedicated access, Single-cell RNA-seq of 1.3 Million Mouse Brain Cells using SCANPY 1.8.1 Toolkit, score= 686 seconds to compete, total cost to complete $0.70. source: https://github.com/clara-parabricks/rapids-single-cell-examples#example-2-single-cell-rna-seq-of-13-million-mouse-brain-cells New-1: Testing as of Feb 5th 2022. Google Cloud instance n2-standard-64, 3rd Gen Intel Xeon Scalable 64vCPUs, 256GB Memory, 257GB Persistant Disk, NIC bandwidth 32Gbps, $3.10 cost per hour dedicated access, Rocky Linux 8.5, Linux version 4.18.0-240.22.1.el8_ |
|||||||||||||||||||
| 3rd party stat: By 2025, an estimated 40% of employees will work remotely. | https://www.consultancy.eu/news/5273/research-40-of-employees-will-work-from-home-by-2025#:~:text=By%202025%2C%2040%25%20of%20employees%20around%20the%20world,from%20businesses%20with%20%245%20billion%20plus%20in%20revenues | |||||||||||||||||||
| 58% of the workforce now needs new skill sets to in order to do their jobs successfully. | https://www.gartner.com/en/newsroom/press-releases/2021-02-03-gartner-hr-research-finds-fifty-eight-percent-of-the-workforce-will-need-new-skill-sets-to-do-their-jobs-successfully | |||||||||||||||||||
| In addition, our real-world testing gave us the data we needed to justify not only refreshing sooner, but also increasing the computing capability given the shift ot the latest OS and modern software applications…This data showed a faster refresh to a higher performing PC can pay for itself in less than a year. | Source: Internal, Intel | |||||||||||||||||||
| Featuring Intel Threat Detection, we are the first and only business PC with hardware-based ransomware detection. | The Intel vPro platform delivers the first and only silicon-enabled AI threat detection to help stop ransomware and cryptojacking attacks for Windows-based systems. Intel TDT Anomalous Behavior Detection (ABD) is a hardware-based control flow monitoring and anomaly detection solution able to monitor business apps for early indicators of compromise, leveraging the Intel CPU to build dynamic AI models of “good” application behavior. See www.intel.com/PerformanceIndex (platforms) for details. No product or component can be absolutely secure. | |||||||||||||||||||
| In fact, in a survey of businesses that have deployed Intel vPro, they report close to a 200% return on investment | A Forrester Total Economic Impact™ Study Commissioned By Intel, January 2021 https://tools.totaleconomicimpact.com/go/intel/vproplatform/ From the information provided in the interviews and survey, Forrester constructed a Total Economic Impact™ framework for those organizations considering an investment in the Intel vPro® platform. The objective of the framework is to identify the cost, benefit, flexibility, and risk factors that affect the investment decision. Forrester took a multistep approach to evaluate the impact that the Intel vPro platform can have on an organization. |
|||||||||||||||||||
| The 12th Gen Intel Core i9-12900 desktop processor provides up to 23% faster application performance than the competition when using Microsoft Excel during a Zoom video conference call, and up to 46% faster with Power BI while on a Zoom call. | As measured by Collaboration with Excel workflow as of Feb. 9, 2022. For workloads and configurations visit https://www.Intel.com/PerformanceIndex. Results may vary. As measured by Collaboration with Power BI workflow as of Feb. 9, 2022. For workloads and configurations visit www.Intel.com/PerformanceIndex. Results may vary. |
|||||||||||||||||||
| I encourage you to review our CoalFire White Paper. | CoalFire White Paper Link | |||||||||||||||||||
| 29 Federated international medical centers. 80K brain tumor diagnosis each year wordwide. 99% accuracy of model trained for brain tumor detection | Venture Beat: Intel partners with Penn Medicine to develop brain tumor classifier | May 2020 | ||||||||||||||||||
| Xeon continue to deliver big generation gains for healthcare workloads 57% for NAMD vs previous gen 60% for GROMACS vs previous gen 64% for LAMMPs vs previous gen 61% for RELION vs previous gen | See [108] at https://www.intel.com/3gen-xeon-config. Results may vary | February 2021 | ||||||||||||||||||
| 66% higher AI inference performance | See [122] at https://www.intel.com/3gen-xeon-config. Results may vary. | |||||||||||||||||||
| Up to 50% reduction in CAPEX build costs. Up to 95% reduction in cooling OPEX. Up to 10x increase in computing density with liquid immersion cooling | Source: Submer. https://submer.com/business-cases/ | March 2022 | ||||||||||||||||||
| ATSM-150 outperforms NVIDIA A10 for mdeia analytics by 1.48x with AVC and 1.14x with HEVC | 1S Intel® Xeon® 6342, 64GB DDR4-3200, Ubuntu 20.04 Kernel 5.10.54+prerelease features hosting 1x ATSM-150. Media Delivery and Media Analytics Solution Stacks: Agama 407 running HEVC and AVC Decode and ResNet50 v1.5. Tested by Intel as of 5/1/2022 1S AMD EPYC 7742, 64GB DDR4-3200, Ubuntu 20.04 hosting 1x NVIDIA A10. Media Delivery and Media Analytics Solution Stacks: Deepstream 6.0 NGC Container running HEVC and AVC Decode and ResNet50 v1.5. Tested by Intel as of 3/30/2022 |
March and May 2022 |