Here’s our recent Medium blog that addresses Habana’s strategy behind its use of software and hardware standards to improve data center performance and efficiency.
In a field with fast-paced development such as AI, it’s incredibly important to think of end-user deployment systems. Questions end users encounter today are: how to ensure that the current design decisions and choices in selecting hardware and software will not “lock in” the system to one specific set of vendors and technologies? And, in the future, how viable will it be to take advantage of new and better hardware or software components without having to perform fork-lift upgrades that may increase project cost and risk, and may impact its schedule? At Habana, we believe the answers to these questions lie in industry collaboration to drive standardization and simplification of technologies that lower the deployment bar for customers, letting them customize AI systems to suit their specific requirements, while also having the freedom to work with an array of vendors. This commitment to standards results in lower total cost of ownership (TCO) for our customers’ inference and training systems. Three examples of this approach: the Goya-Glow software integration, RoCE RDMA integration in the Gaudi AI Training Processor, and Gaudi support for the OCP-OAM hardware standardization.
Glow
Glow is an open-source machine learning intermediate compiler and runtime that allows one to more rapidly design and optimize new silicon products for machine learning, giving implementers the flexibility to map to different underlying hardware. It enables the entire ecosystem of hardware developers and researchers to focus their efforts on building next-gen hardware accelerators that can be supported by deep learning frameworks like PyTorch. Habana Labs Goya Inference Processor was the first AI processor to implement and open-source the Glow compiler back-end.
Glow can be used as a common layer for improved ML performance on top of any supported hardware accelerator. Applications include computer vision, recommendation or personalization, natural language processing, and others. At the first Glow Summit (Apr ’19), Facebook announced the first experimental back-end for the Glow compiler and runtime to target Habana’s Goya Inference accelerator, allowing Habana customers to use Glow to drive their hardware accelerators. The code is available here. In addition, this recent blog gives a good sense of how Glow fits into the features and benefits of the latest release of the PyTorch framework.
There are potential Glow-to-Habana integration alternatives that may be applied: a full Glow compilation flow in which Glow performs the entire compilation, including the front-end phases such as graph creation, quantization profiling and optimizations, algorithmic optimizations, operator fusing and back-end stages such as hardware mapping and memory allocation. Alternatively, mixed integration models may be applied in which Glow performs part of the front-end phases and hands off to the Habana Graph compiler for execution of the remaining optimization phases and the back-end generation.
RoCE: RDMA over Converged Ethernet
At Habana, we believe that AI scaling is fundamentally a networking challenge. The most advanced networking technology for scaling is RoCE, an industry-standard protocol for RDMA over Converged Ethernet. RoCE simply encapsulates the RDMA payload and header inside the Ethernet/IP/UDP header. This enables standard Ethernet networking gear to be used by endpoints that support the RDMA protocol.
Gaudi is the only AI processor to integrate RoCE networking interfaces onto the processor chip itself. These RoCE engines are critical for offloading and driving the communication between Gaudi processors needed during training. Integrated RoCE enables scale-up using standard Ethernet switches and cables without relying on proprietary interfaces, which some solutions require and which lock in customer hardware selection — limiting choice, and potentially stymying performance and efficiency.
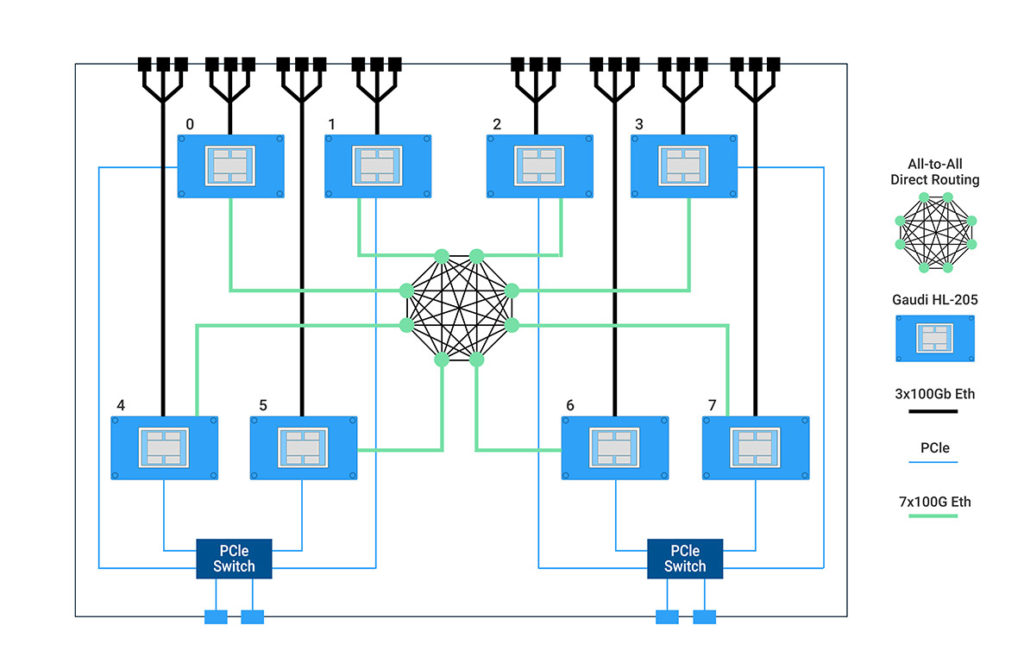
Below is an example of the Habana HLS-1 server, which comprises an eight Gaudi OCP OAM- compliant card system, where seven out of the ten 100 Gb Ethernet ports available per Gaudi processor are connected in an all-to-all manner between the eight cards. The additional three 100 Gb Ethernet ports are routed externally for scale-out, providing different kinds of connection topologies and clustering, using standard Ethernet off-the-shelf switches and cables.
HLS-1 Server: Ethernet-based Connectivity Diagram
Open Compute Project Accelerator Module
The OCP OAM (Open Accelerator Module) specification defines the hardware form factor, interconnects and specifications as part of the Open Compute Project (OCP), an organization that shares designs of data center products and best practices among companies standardizing AI data center hardware. The OAM objective is to enable customers to interchangeably use hardware components from different vendors in a smooth and verified way, helping them to avoid vendor lock-in.
Habana was the first in the AI processor industry to develop and introduce (in June ’19) the AI training accelerator card, the GAUDI HL-205 — a mezzanine card compliant with the OCP-OAM specification, supporting 10 ports of 100Gb Ethernet or 20 ports of 50Gb Ethernet.
Habana Labs Gaudi AI Training Processor HL-205

Habana’s mission is to give customers the ultimate in AI performance while making deployment easy, flexible and efficient. For more information, see our inference and training web content.