
With Habana’s SynapseAI 1.13.0 release, users can run Fine Tune the Llama2 70B model using only 8 Gaudi2 Accelerators.
News & Discussion
With Habana’s SynapseAI 1.13.0 release, users can run Fine Tune the Llama2 70B model using only 8 Gaudi2 Accelerators.

Bringing forth numerous enhancements and updates for an improved user experience.
One of the main challenges in training Large Language Models (LLMs) is that they are often too large to fit on a single node or even if they fit, the training may be too slow. To address this issue, their training can be parallelized across multiple Gaudi accelerators (HPUs).

If you want to train a large model using Megatron-DeepSpeed, but the model you want is not included in the implementation, you can port it to the Megatron-DeepSpeed package. Assuming your model is transformer-based, you can add your implementation easily, basing it on existing code.
In this release, we’ve upgraded versions of several libraries, including DeepSpeed 0.9.4, PyTorch Lightning 2.0.4 and TensorFlow 2.12.1.
This Intel NewsByte was originally published in the Intel Newsroom. Habana Gaudi2 and 4th Gen Intel Xeon Scalable processors deliver leading performance and optimal cost savings for AI training. What’s New: Today, MLCommons published results of its industry AI performance benchmark, MLPerf Training 3.0, in which both the Habana® Gaudi®2 deep learning accelerator and the 4th Gen Intel® … Read more

We’re excited to participate in this year’s ISC High Performance Compute 2023 event in Hamburg Germany.

Equus and Habana have teamed up to simplify the process of testing, implementing and deploying AI infrastructure based on Habana Gaudi2 processors. Customers can now leverage Equus Lab-as-a-Service to reach their innovation goals while addressing the challenges created by large-scale lab infrastructures. Gaudi2 is expressly architected to deliver high-performance, high-efficiency deep learning training and inference … Read more

Announcing a new End-to-End use case showing Training of a semantic segmentation model for Autonomous Driving

In the 1.9 release, we’ve upgraded versions of several libraries, including PyTorch Lightning 1.9.4, DeepSpeed 0.7.7, fairseq 0.12.3, and Horovod v0.27.0.

In this article, you’ll learn how to easily deploy multi-billion parameter language models on Habana Gaudi2 and get a view into the Hugging Face performance evaluation of Gaudi2 and A100 on BLOOMZ.

AWS and Habana collaborated to enable EFA Peer Direct support on the Gaudi-based AWS DL1 instances, offering users significant improvement in multi-instance model training performance.

AI is becoming increasingly important for retail use cases. It can provide retailers with advanced capabilities to personalize customer experiences, optimize operations, and increase sales. Habana has published a new Retail use case showing an example of finetuning a PyTorch YOLOX model for managing shelf space and shelf inventory in the Retail environment. This … Read more
In this article, you will learn how to use Habana® Gaudi®2 to accelerate model training and inference, and train bigger models with 🤗 Optimum Habana.

With Habana’s SynapseAI 1.8.0 release support of DeepSpeed Inference, users can run inference on large language models, including BLOOM 176B.

Our blog today features a Riken white paper, initially prepared and published by the Intel Japan team in collaboration with Kei Taneishi, research scientist with Riken’s Institute of Physical and Chemical Research. The paper should be useful for those in the medical research domain as it addresses research cases utilizing both computer vision and natural … Read more
We have upgraded versions of several libraries with SynapseAI 1.8.0, including PyTorch 1.13.1, PyTorch Lightning 1.8.6 and TensorFlow 2.11.0 & 2.8.4.

In this post, we show you how to run Habana’s DeepSpeed enabled BERT1.5B model from our Model-References repository.

In this paper we’ll show how Transfer Learning is an efficient way to train an existing model on a new and unique dataset with equivalent accuracy and significantly less training time.

Habana’s Gaudi2 delivers amazing deep learning performance and price advantage for both training as well as large-scale deployments, but to capture these advantages developers need easy, nimble software and the support of a robust AI ecosystem. This week our COO, Eitan Medina, connected with Karl Freund, founder and principal analyst of Cambrian-AI Research, to discuss … Read more
This tutorial provides example training scripts to demonstrate different DeepSpeed optimization technologies on HPU. This tutorial will focus on the memory optimization technologies, including Zero Redundancy Optimizer(ZeRO) and Activation Checkpointing.

The SDSC Voyager supercomputer is an innovative AI system designed specifically for science and engineering research at scale.

In this post, we will learn how to run PyTorch stable diffusion inference on Habana Gaudi processor, expressly designed for the purpose of efficiently accelerating AI Deep Learning models.
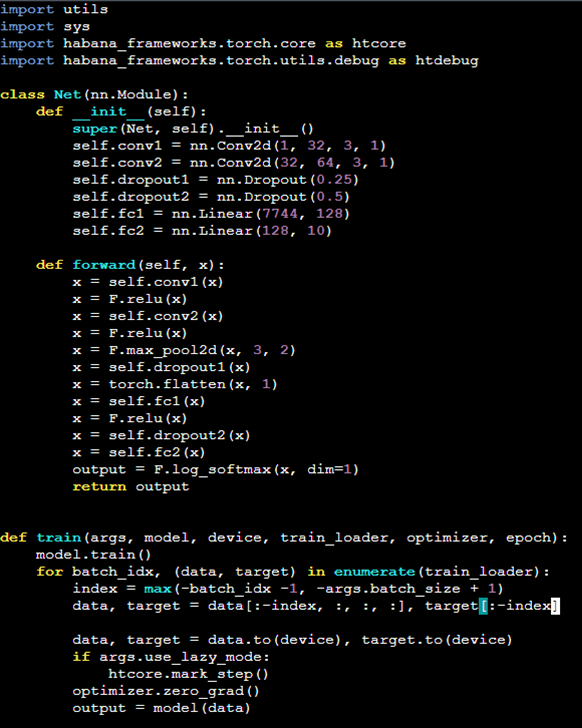
In training workloads, there may occur some scenarios in which graph re-compilations occur. This can create system latency and slow down the overall training process with multiple iterations of graph compilation. This blog focuses on detecting these graph re-compilations.